


















自社コンテンツをAI学習から守る!「Google-Extended」等のrobots.txt設定とメリット・デメリット【2026年最新】

「順位は変わっていないのに、流入が減っている…」
2025年以降、多くのSEO担当者が直面しているこの現象の背景には、AI Overviews(AIによる概要)の急速な普及があります。AI Overviewsは月間15億インプレッションを記録しており(2025年第1四半期)、検索画面上で情報が完結してしまう「ゼロクリック検索」を加速させています。
その一方で、あなたが時間とコストをかけて作ったコンテンツが、AIの学習データとして無断利用されているリスクも高まっています。では、どう対応すれば良いのか。
この記事では、SEO順位を守りながらコンテンツ資産を守る最適なrobots.txt戦略を、2026年最新情報をもとに徹底解説します。

- 目次
robots.txtとAIクローラーの基礎
robots.txtとは?
robots.txt は、Webサイトのルートディレクトリ(例:https://example.com/robots.txt)に設置するテキストファイルです。検索エンジンや各種クローラーに対して、「どのページをクロールしてよいか」「どのページはクロールしないでほしいか」を指示します。
重要なのは、robots.txtはあくまで”紳士協定”であり、法的強制力はないという点です。GoogleやOpenAIなど主要企業は公式に遵守を宣言していますが、すべてのクローラーが従うとは限りません(後述)。
なぜ今「AIクローラー対策」が必要なのか?
ChatGPTやGeminiに代表される生成AIは、インターネット上の膨大なテキストを学習して作られています。自身で専門家に監修を依頼したコラム、独自調査レポート、試行錯誤を経て磨いたノウハウも、AIの学習データとして無断利用されている可能性があります。
特にマーケターやSEO担当者にとって重要なのは、コンテンツへの投資を守りながら、SEO順位や検索流入を維持するというバランスです。正しく設定すれば、Googleの検索順位に一切影響を与えずにAI学習をブロックできます。
【最重要】Google-Extendedとは?よくある誤解を解説
Google-Extendedの正体
Google-Extendedは、Googleが2023年9月に公式発表したAI学習専用のクローラーです。収集したデータは以下のサービスの改善に使用されます。
- Gemini(旧Google Bard)
- Vertex AI API(Google CloudのAIプラットフォーム)
検索SEOへの影響は「ゼロ」と公式が明言
Googleは公式ドキュメントで明確に述べています。
Google 検索でのサイトの登録と掲載順位に Google-Extended が影響することはありません。つまり、Google-Extendedをブロックしても、Googlebotによる検索クロール・インデックスには一切影響しません。
【ここが盲点】AI OverviewsはGoogle-Extendedでは制御できない
多くの記事が見落としている、最も重要なポイントです。
AI Overviewsは「検索機能の一部」として動作するため、Googlebotが制御しています。Google-Extendedではありません。
さらに深刻なのは、Google-ExtendedをブロックしてもAI OverviewsがリアルタイムにあなたのページをFetchすることは防げないという事実です。現在EUの規制当局がこの点を問題視し、Googleに対する調査が始まっています(2025年末〜)。
| クローラー | 用途 | ブロック時の影響 |
|---|---|---|
| Googlebot | 通常の検索インデックス+AI Overviewsへのリアルタイムデータ取得 | 検索順位・AI概要の両方に影響 |
| Google-Extended | GeminiとVertex AI APIの学習データ収集 | 検索・AI Overviewsには影響なし |
つまり、Google-Extendedのブロックは「Geminiの学習データに使わせない」という意味であり、「AI Overviewsに引用させない」とは別の話です。この区別を正確に理解することが、戦略立案の出発点になります。
主要AIクローラー完全一覧(2026年版)
robots.txtで制御できる主要なAIクローラーを網羅しました。
| User-agent名 | 運営企業 | 用途 | robots.txt遵守 |
|---|---|---|---|
Google-Extended | Gemini・Vertex AI学習 | 公式確認済 | |
GPTBot | OpenAI | ChatGPT学習用クローラー | 公式確認済 |
ChatGPT-User | OpenAI | ChatGPTのリアルタイム検索 | 公式確認済 |
OAI-SearchBot | OpenAI | SearchGPTのインデックス | 公式確認済 |
ClaudeBot | Anthropic | Claude学習用クローラー | 公式確認済 |
anthropic-ai | Anthropic | Anthropic AI学習 | 公式確認済 |
CCBot | Common Crawl | Stable Diffusion等、多数のAIが利用 | 公式確認済 |
Bytespider | ByteDance(TikTok親会社) | AI学習 | 遵守不明 |
meta-externalagent | Meta | LLaMAなどMeta AI学習 | 公式確認済 |
FacebookBot | Meta | Metaサービス用 | 公式確認済 |
PerplexityBot | Perplexity AI | Perplexity AI検索インデックス | 無視報告あり |
具体的なrobots.txt設定コード例(コピペOK)
【ケース1】AI学習のみブロック(SEO・AI Overviewsは維持)
SEO順位を守りながら、Gemini等のAI学習データとしての利用を防ぐ、最もバランスの取れた設定です。マーケターが最初に検討すべきパターンです。
# 通常の検索エンジンは許可
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Allow: /
# AIトレーニング用クローラーをブロック
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: meta-externalagent
Disallow: /
Sitemap: https://example.com/sitemap.xml【ケース2】AI学習はブロック、AI検索(参照)は許可
学習データとしての利用は断りながら、ChatGPTやPerplexityのWeb検索経由での引用・トラフィックは受け入れる戦略的設定です。AI検索が普及する中で、新たな流入経路を確保したいSEOメディアに最適です。
User-agent: *
Allow: /
# AI学習クローラー:ブロック
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: meta-externalagent
Disallow: /
# AI検索クローラー:許可(引用・トラフィック獲得のため)
User-agent: ChatGPT-User
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
Sitemap: https://example.com/sitemap.xml【ケース3】有料コンテンツ・特定ディレクトリのみ保護
無料の一般公開コンテンツはAI検索にも露出させてリード獲得に活用しながら、有料コンテンツや機密レポートだけをAIから保護する設定です。BtoBサービスやEC、有料会員サイトに有効です。
User-agent: *
Allow: /
# 有料・機密コンテンツのみAI学習からブロック
User-agent: GPTBot
Disallow: /premium/
Disallow: /members/
Disallow: /reports/
User-agent: Google-Extended
Disallow: /premium/
Disallow: /members/
Disallow: /reports/
User-agent: ClaudeBot
Disallow: /premium/
Disallow: /members/
Disallow: /reports/
User-agent: anthropic-ai
Disallow: /premium/
Disallow: /members/
Disallow: /reports/
Sitemap: https://example.com/sitemap.xml【ケース4】全AIクローラーを完全ブロック
著作権保護を最優先にする場合の設定です。AI検索経由の流入機会は失われますが、コンテンツの独自性がビジネス価値の根幹にある場合に適した選択です。
# AIクローラー完全ブロック
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: meta-externalagent
Disallow: /
User-agent: FacebookBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
# 通常の検索エンジンは許可
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
Sitemap: https://example.com/sitemap.xmlAIクローラーをブロックするメリット・デメリット
メリット
1. オリジナルコンテンツの著作権保護
専門家監修コラム、独自調査データ、競合優位性の源泉となるノウハウが、AIに無断で学習・出力されるリスクを低減できます。
2. 有料コンテンツ・会員限定コンテンツの保護
サブスクリプションコンテンツや購入者限定レポートが、AI経由で無料提供されてしまうリスクを防ぎます。
3. ブランドイメージのコントロール
AIが自社コンテンツを不正確に引用・要約するリスクを下げ、誤情報の拡散を防ぎます。
4. 検索SEOへの影響がない(Google-Extendedの場合)
Googleが公式に明言している通り、Google-Extendedのブロックは検索順位に一切影響しません。コストゼロで今すぐ実施できる対策です。
5. サーバー負荷の軽減
AIクローラーは頻繁に大量のリクエストを送ることがあります。不要なクローラーをブロックすることでサーバーリソースを節約できます。
デメリット・注意点
1. AI検索(Perplexity・ChatGPT検索等)での露出機会を失う
AI検索エンジン経由のトラフィックは今後さらに拡大する見込みです。全ブロックはこの新しい流入チャネルを遮断します。
2. 完全な防御にはならない
robots.txtはあくまで”お願い”です。Perplexityのように無視するサービスも報告されています。悪意あるクローラーは設定を無視します。
3. 設定漏れのリスク
AIクローラーは新たなものが次々と登場します。設定した時点では網羅できていても、半年後には新クローラーへの対応が必要になります。
4. 間接的なブランド認知機会の損失
「AIに聞いたら自社の名前が出てきた」という間接的な認知経路が失われます。AI検索が主要な情報収集手段になる時代において、これは見えにくいが無視できない機会コストです。
メリット・デメリット比較表
| 項目 | AIクローラーをブロック | ブロックしない |
|---|---|---|
| Google検索順位 | 影響なし | 影響なし |
| AI Overviews掲載 | 影響なし(Google-Extended限定) | 影響なし |
| Geminiでの引用・回答生成 | 学習データから除外される | 引用される可能性あり |
| ChatGPT回答での引用 | なし | あり(可能性) |
| AI検索(Perplexity等)の引用 | なし(ただし遵守保証なし) | あり |
| コンテンツ著作権保護 | 強い | 弱い |
| AI検索からのトラフィック | 少ない | 多い可能性 |
| サーバー負荷 | 軽減 | クローラー分の負荷あり |
| 設定・メンテナンスの手間 | あり(定期更新必要) | なし |
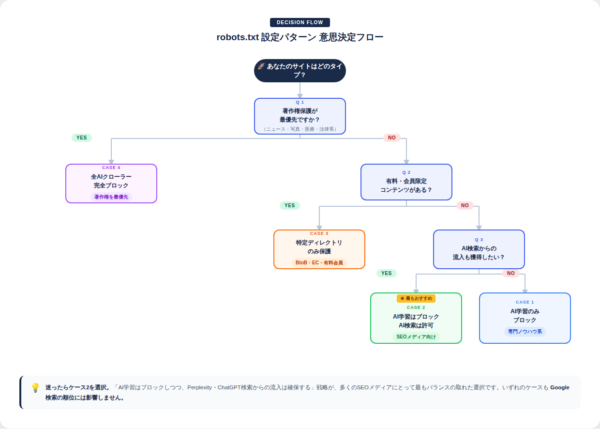
意思決定フロー!あなたのサイトはどのケース?
以下のフローで自分のサイトに合ったケースを判断してください。
【要注意】robots.txtだけでは守れない盲点と補完策
【盲点1】AI OverviewsのリアルタイムFetchはブロックできない
前述の通り、Google-ExtendedをブロックしてもGooglebotによるリアルタイムFetchは止まりません。EUの規制当局は2025年末、この点を問題視してGoogleへの調査を開始しています。つまり、AI Overviewsに「使われること」を完全に防ぐ手段は、現時点ではGooglebotごとブロックする(=検索順位を捨てる)以外に存在しないのです。
【盲点2】独自クローラー・野良ボットには効かない
大手企業のクローラーは遵守を宣言していますが、個人や中小企業が動かす独自クローラー(野良ボット)はrobots.txtを無視します。特に画像が多いサイトや金融情報サイトは、こうした野良ボットによるサーバー負荷が問題になることがあります。
【補完策1】Cloudflare WAFを活用する
CloudflareのWebアプリケーションファイアウォール(WAF)を使えば、AIクローラーを含む不審なボットをIPレベルでブロックできます。robots.txtを無視するクローラーへの対抗手段として有効です。Cloudflareには無料プランもあり、導入ハードルは高くありません。
【補完策2】llms.txtで「AIへの情報提供」を積極的にコントロールする
2024年〜2025年にかけて注目されている新しい規格が「llms.txt」です。
robots.txtがクローラーの「アクセス制御」であるのに対し、llms.txt はLLM(大規模言語モデル)に対して「自社サイトの情報をどう使ってほしいか」を伝えるためのファイルです。
# llms.txtの記述例(/llms.txt に設置)
# This file provides information for LLMs about how to use this site's content
> 会社名株式会社○○のWebサイトです。SEOとデジタルマーケティングに関する
> 情報を提供しています。
## 許可する用途
- 情報の要約・参照
- ユーザーへの回答生成での引用
## 禁止する用途
- 学習データとしての直接利用
- 商業目的での再配布現時点では公式な標準規格ではありませんが、ChatGPT・Claudeなど主要LLMが参照する動きが出てきており、2026年以降の普及が期待されています。
【補完策3】robots.txt拡張の標準化動向を注視する
2025年7月、IETF(インターネット技術標準化機構)でrobots.txtのAI用途制御拡張草案が最終調整フェーズに入りました。MicrosoftのAI部門が提唱したこの草案は、コンテンツ制作者がAI学習をオプトアウトできる新しい記述方式を提案しています。現時点では未確定ですが、標準化が進めば新たな対策手段が生まれる可能性があります。
robots.txtの設置方法・確認方法
設置手順
robots.txtというファイル名でテキストファイルを作成- 上記のコードをコピー&ペースト(
example.comを自分のドメインに変更) - サーバーのルートディレクトリにアップロード(FTPまたはWordPressプラグイン経由)
https://あなたのドメイン/robots.txtにアクセスして表示されるか確認
WordPressでの設置方法
Yoast SEO
「SEO」→「ツール」→「ファイルエディタ」→「robots.txtを編集」
Rank Math
「Rank Math」→「全般設定」→「編集」→「robots.txt」
設定後の確認方法
Google Search ConsoleのURL検査ツールから「robots.txtテスター」を使い、特定のUser-agentでのアクセス可否を確認しましょう。設定ミスがないかを必ずチェックしてください。
定期メンテナンスチェックリスト
robots.txtは設定したら終わりではありません。半年に1回を目安に以下を確認しましょう。
- 新しいAIクローラーが登場していないか(各AI企業の公式ドキュメントを確認)
- 既存のUser-agent名が変更されていないか
- サイトのディレクトリ構成が変わり、Disallowのパスが正しいか
- Google Search Consoleでクロールエラーが発生していないか
マーケターが今すぐ取るべきrobots.txt戦略
AI学習からコンテンツを守ることと、SEO・検索流入を維持することは両立できます。ただし、「全部ブロック」が正解とは限りません。AI検索が主要な情報収集チャネルとして成長する中、戦略的な判断が求められます。
今すぐ対応すべき4つのアクション
- Google-Extendedのブロックを即実施
検索順位への影響ゼロが公式確認済みで、デメリットがほぼない。まずここから始める。 - AI検索クローラー(ChatGPT-User・PerplexityBot)は慎重に判断
「学習ブロック、検索参照は許可」という使い分け(ケース2)が、多くのSEOメディアにとってベストバランス。 - 有料・機密コンテンツは必ず個別に保護
全体ブロックより「守るべき場所を明確にした部分ブロック」が現実的かつ効果的。 - 半年に1回のメンテナンスを習慣化
AIクローラーは急速に増加・変化しています。設定は一度でなく継続的に見直す必要があります。
robots.txtはあくまで「紳士協定」です。完璧な防御策とは言えませんが、現時点で最も手軽かつ即効性のあるコンテンツ保護手段であることに変わりありません。同時に、Cloudflare WAFやllms.txtなど補完策も視野に入れながら、自社のコンテンツ戦略に合わせた多層的な防衛を構築していきましょう。
よくある質問(FAQ)
Google-Extendedをブロックすると、Googleの検索順位は下がりますか?
下がりません。Googleが公式ドキュメントで明確に「検索のインデックスやランキングに影響しない」と述べています。
Google-ExtendedをブロックするとAI Overviewsに表示されなくなりますか?
AI Overviewsには影響しません。AI OverviewsはGooglebotが制御しており、Google-Extendedとは別のクローラーです。
robots.txtに書いたのにAIがコンテンツを出力している。なぜ?
考えられる理由は2つです。(1) robots.txtが設定される以前にすでに学習が完了している(過去のデータは削除されない)。(2) そのAIサービスがrobots.txtを遵守していない。どちらの場合も、robots.txtは「これ以上学習させない」ための措置であり、過去の学習を取り消す効果はありません。
Perplexityはrobots.txtを無視すると聞きましたが、設定する意味はありますか?
他のAIクローラー(GPTBot、Google-Extended等)への効果は確実にあるため、設定しない理由はありません。Perplexityへの対策はCloudflare WAFなどのIPレベルブロックを検討してください。
WordPressで設定する場合、プラグインとFTPどちらが良いですか?
初心者にはYoast SEOやRank Mathのプラグイン経由が安全です。誤って他の設定を書き換えるリスクが低く、設定内容を画面上で確認しながら編集できます。
設定後、すぐに効果が出ますか?
robots.txtの変更は、各AIクローラーが次回クロール時に読み込んで初めて適用されます。通常数日〜数週間で反映されますが、すでに学習済みのデータには遡って影響しません。
















